使用顺序API构建图像分类器 1 2 3 4 5 from tensorflow import kerasimport matplotlib.pyplot as pltimport numpy as npimport pandas as pd%matplotlib inline
1 2 fashion_mnist = keras.datasets.fashion_mnist (X_train_full,y_train_full),(X_test,y_test) = fashion_mnist.load_data()
1 X_train_full.shape,X_train_full.dtype
((60000, 28, 28), dtype('uint8'))
1 2 X_valid, X_train = X_train_full[:5000 ]/255.0 , X_train_full[5000 :]/255.0 y_valid, y_train = y_train_full[:5000 ], y_train_full[5000 :]
1 class_names = ["T-shirt/top" , "Trouser" , "Pullover" , "Dress" , "Coat" , "Sandal" , "Shirt" , "Sneaker" , "Bag" , "Ankle boot" ]
1 2 3 4 5 6 plt.figure(figsize=(10 ,8 )) for i in range (10 ): plt.subplot(2 ,5 ,i+1 ) plt.imshow(X_train[i],cmap='gray' ) plt.axis('off' ) plt.title(class_names[y_train[i]])
1 2 3 4 model = keras.Sequential([keras.layers.Flatten(input_shape=[28 ,28 ]), keras.layers.Dense(300 ,activation=keras.activations.relu), keras.layers.Dense(100 ,activation=keras.activations.relu), keras.layers.Dense(10 ,activation=keras.activations.softmax)])
初始化时,对于每一层的权重和偏置可以使用kernel_initializer或bias_initializer进行初始化;\input_shape。
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
flatten (Flatten) (None, 784) 0
_________________________________________________________________
dense (Dense) (None, 300) 235500
_________________________________________________________________
dense_1 (Dense) (None, 100) 30100
_________________________________________________________________
dense_2 (Dense) (None, 10) 1010
=================================================================
Total params: 266,610
Trainable params: 266,610
Non-trainable params: 0
_________________________________________________________________
[<keras.layers.core.Flatten at 0x294b10e2b50>,
<keras.layers.core.Dense at 0x294b1182a90>,
<keras.layers.core.Dense at 0x294b1141e20>,
<keras.layers.core.Dense at 0x294b11817f0>]
1 model.layers[1 ] == model.get_layer('dense' )
True
1 weights, bias = model.layers[1 ].get_weights()
array([[ 0.00432374, 0.069911 , 0.04554318, ..., 0.02112412,
-0.05035692, -0.04687664],
[-0.02890603, 0.06612819, 0.05927478, ..., -0.04826843,
0.00918571, -0.03757042],
[-0.0468495 , -0.05732308, 0.00990029, ..., -0.00668625,
-0.00170599, 0.01458585],
...,
[-0.03658697, -0.03046996, 0.06218758, ..., 0.07221685,
-0.03757465, 0.06432179],
[ 0.02678267, -0.00753582, 0.02744661, ..., 0.07104121,
-0.02597448, 0.04335685],
[ 0.02518395, 0.05691384, 0.00831134, ..., -0.05676897,
0.04779277, -0.06324223]], dtype=float32)
array([0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.], dtype=float32)
1 2 3 model.compile (loss=keras.losses.sparse_categorical_crossentropy, optimizer=keras.optimizers.SGD(learning_rate=0.01 ), metrics=keras.metrics.sparse_categorical_accuracy)
注意:我们使用的损失函数如上所示,因为我们具有稀疏标签(即对于每个实例,只有一个目标类索引,例子情况下为0~9),并且这些类都是互斥的,\categorical_crossentropy。\sigmoid激活函数,且使用binary_crossentropy损失。\keras.utils.to_categorical(),反之则使用np.argmax(axis=1)
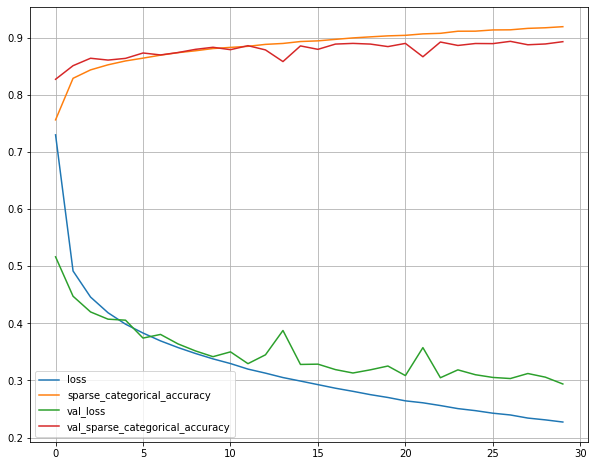
1 history = model.fit(X_train,y_train,epochs=30 ,validation_data=(X_valid,y_valid))
Epoch 1/30
1719/1719 [==============================] - 12s 5ms/step - loss: 0.7298 - sparse_categorical_accuracy: 0.7560 - val_loss: 0.5163 - val_sparse_categorical_accuracy: 0.8270
Epoch 2/30
1719/1719 [==============================] - 7s 4ms/step - loss: 0.4916 - sparse_categorical_accuracy: 0.8287 - val_loss: 0.4473 - val_sparse_categorical_accuracy: 0.8508
Epoch 3/30
1719/1719 [==============================] - 7s 4ms/step - loss: 0.4459 - sparse_categorical_accuracy: 0.8434 - val_loss: 0.4199 - val_sparse_categorical_accuracy: 0.8638
Epoch 4/30
1719/1719 [==============================] - 7s 4ms/step - loss: 0.4185 - sparse_categorical_accuracy: 0.8523 - val_loss: 0.4072 - val_sparse_categorical_accuracy: 0.8606
Epoch 5/30
1719/1719 [==============================] - 7s 4ms/step - loss: 0.3985 - sparse_categorical_accuracy: 0.8591 - val_loss: 0.4054 - val_sparse_categorical_accuracy: 0.8636
Epoch 6/30
1719/1719 [==============================] - 7s 4ms/step - loss: 0.3830 - sparse_categorical_accuracy: 0.8640 - val_loss: 0.3741 - val_sparse_categorical_accuracy: 0.8730
Epoch 7/30
1719/1719 [==============================] - 7s 4ms/step - loss: 0.3692 - sparse_categorical_accuracy: 0.8692 - val_loss: 0.3805 - val_sparse_categorical_accuracy: 0.8696
Epoch 8/30
1719/1719 [==============================] - 7s 4ms/step - loss: 0.3576 - sparse_categorical_accuracy: 0.8736 - val_loss: 0.3639 - val_sparse_categorical_accuracy: 0.8738
Epoch 9/30
1719/1719 [==============================] - 7s 4ms/step - loss: 0.3472 - sparse_categorical_accuracy: 0.8769 - val_loss: 0.3516 - val_sparse_categorical_accuracy: 0.8794
Epoch 10/30
1719/1719 [==============================] - 7s 4ms/step - loss: 0.3377 - sparse_categorical_accuracy: 0.8808 - val_loss: 0.3416 - val_sparse_categorical_accuracy: 0.8830
Epoch 11/30
1719/1719 [==============================] - 7s 4ms/step - loss: 0.3295 - sparse_categorical_accuracy: 0.8828 - val_loss: 0.3500 - val_sparse_categorical_accuracy: 0.8788
Epoch 12/30
1719/1719 [==============================] - 7s 4ms/step - loss: 0.3198 - sparse_categorical_accuracy: 0.8847 - val_loss: 0.3294 - val_sparse_categorical_accuracy: 0.8858
Epoch 13/30
1719/1719 [==============================] - 9s 5ms/step - loss: 0.3128 - sparse_categorical_accuracy: 0.8881 - val_loss: 0.3449 - val_sparse_categorical_accuracy: 0.8784
Epoch 14/30
1719/1719 [==============================] - 8s 4ms/step - loss: 0.3050 - sparse_categorical_accuracy: 0.8897 - val_loss: 0.3874 - val_sparse_categorical_accuracy: 0.8580
Epoch 15/30
1719/1719 [==============================] - 8s 4ms/step - loss: 0.2989 - sparse_categorical_accuracy: 0.8931 - val_loss: 0.3280 - val_sparse_categorical_accuracy: 0.8854
Epoch 16/30
1719/1719 [==============================] - 8s 5ms/step - loss: 0.2927 - sparse_categorical_accuracy: 0.8942 - val_loss: 0.3285 - val_sparse_categorical_accuracy: 0.8794
Epoch 17/30
1719/1719 [==============================] - 9s 5ms/step - loss: 0.2864 - sparse_categorical_accuracy: 0.8969 - val_loss: 0.3190 - val_sparse_categorical_accuracy: 0.8886
Epoch 18/30
1719/1719 [==============================] - 8s 4ms/step - loss: 0.2810 - sparse_categorical_accuracy: 0.8994 - val_loss: 0.3130 - val_sparse_categorical_accuracy: 0.8898
Epoch 19/30
1719/1719 [==============================] - 7s 4ms/step - loss: 0.2751 - sparse_categorical_accuracy: 0.9013 - val_loss: 0.3186 - val_sparse_categorical_accuracy: 0.8886
Epoch 20/30
1719/1719 [==============================] - 7s 4ms/step - loss: 0.2702 - sparse_categorical_accuracy: 0.9030 - val_loss: 0.3252 - val_sparse_categorical_accuracy: 0.8842
Epoch 21/30
1719/1719 [==============================] - 7s 4ms/step - loss: 0.2643 - sparse_categorical_accuracy: 0.9039 - val_loss: 0.3085 - val_sparse_categorical_accuracy: 0.8898
Epoch 22/30
1719/1719 [==============================] - 7s 4ms/step - loss: 0.2609 - sparse_categorical_accuracy: 0.9064 - val_loss: 0.3574 - val_sparse_categorical_accuracy: 0.8664
Epoch 23/30
1719/1719 [==============================] - 6s 4ms/step - loss: 0.2561 - sparse_categorical_accuracy: 0.9074 - val_loss: 0.3047 - val_sparse_categorical_accuracy: 0.8922
Epoch 24/30
1719/1719 [==============================] - 6s 4ms/step - loss: 0.2507 - sparse_categorical_accuracy: 0.9111 - val_loss: 0.3185 - val_sparse_categorical_accuracy: 0.8862
Epoch 25/30
1719/1719 [==============================] - 8s 5ms/step - loss: 0.2471 - sparse_categorical_accuracy: 0.9112 - val_loss: 0.3100 - val_sparse_categorical_accuracy: 0.8896
Epoch 26/30
1719/1719 [==============================] - 7s 4ms/step - loss: 0.2427 - sparse_categorical_accuracy: 0.9133 - val_loss: 0.3052 - val_sparse_categorical_accuracy: 0.8894
Epoch 27/30
1719/1719 [==============================] - 7s 4ms/step - loss: 0.2396 - sparse_categorical_accuracy: 0.9136 - val_loss: 0.3033 - val_sparse_categorical_accuracy: 0.8934
Epoch 28/30
1719/1719 [==============================] - 7s 4ms/step - loss: 0.2341 - sparse_categorical_accuracy: 0.9161 - val_loss: 0.3121 - val_sparse_categorical_accuracy: 0.8874
Epoch 29/30
1719/1719 [==============================] - 7s 4ms/step - loss: 0.2310 - sparse_categorical_accuracy: 0.9171 - val_loss: 0.3057 - val_sparse_categorical_accuracy: 0.8888
Epoch 30/30
1719/1719 [==============================] - 7s 4ms/step - loss: 0.2272 - sparse_categorical_accuracy: 0.9190 - val_loss: 0.2938 - val_sparse_categorical_accuracy: 0.8928
我们可以设置validation_split指定用于验证的训练集的比例;\class_weight给代表性不足的类更大的权重。
{'verbose': 1, 'epochs': 30, 'steps': 1719}
1 2 pd.DataFrame(history.history).plot(figsize=(10 ,8 )) plt.grid(True )
1 model.evaluate(X_test,y_test,batch_size=10000 )
1/1 [==============================] - 0s 38ms/step - loss: 61.2780 - sparse_categorical_accuracy: 0.8535
[61.278011322021484, 0.8535000085830688]
1 2 X_new = X_test[:3 ] y_pred = model.predict(X_new).argmax(axis=1 )
1 2 3 4 5 6 plt.figure() for i in range (3 ): plt.subplot(1 ,3 ,i+1 ) plt.imshow(X_new[i],cmap='gray' ) plt.title(class_names[y_pred[i]]) plt.axis('off' )
使用顺序API构建回归MLP 1 2 3 4 5 6 7 8 9 10 11 12 13 from sklearn.datasets import fetch_california_housingfrom sklearn.model_selection import train_test_splitfrom sklearn.preprocessing import StandardScalerhousing = fetch_california_housing() X_train_full, X_test, y_train_full, y_test = train_test_split(housing.data, housing.target, random_state=42 ) X_train, X_valid, y_train, y_valid = train_test_split(X_train_full, y_train_full, random_state=42 ) scaler = StandardScaler() X_train = scaler.fit_transform(X_train) X_valid = scaler.transform(X_valid) X_test = scaler.transform(X_test)
1 2 3 4 5 6 7 8 9 model = keras.models.Sequential([ keras.layers.Dense(30 , activation="relu" , input_shape=X_train.shape[1 :]), keras.layers.Dense(1 ) ]) model.compile (loss="mean_squared_error" , optimizer=keras.optimizers.SGD(lr=1e-3 )) history = model.fit(X_train, y_train, epochs=20 , validation_data=(X_valid, y_valid)) mse_test = model.evaluate(X_test, y_test) X_new = X_test[:3 ] y_pred = model.predict(X_new)
Epoch 1/20
363/363 [==============================] - 2s 6ms/step - loss: 2.6348 - val_loss: 1.4654
Epoch 2/20
363/363 [==============================] - 2s 5ms/step - loss: 0.8950 - val_loss: 0.8080
Epoch 3/20
363/363 [==============================] - 2s 5ms/step - loss: 0.7566 - val_loss: 0.6868
Epoch 4/20
363/363 [==============================] - 2s 5ms/step - loss: 0.7088 - val_loss: 0.7151
Epoch 5/20
363/363 [==============================] - 2s 4ms/step - loss: 0.6756 - val_loss: 0.6320
Epoch 6/20
363/363 [==============================] - 1s 4ms/step - loss: 0.6457 - val_loss: 0.6111
Epoch 7/20
363/363 [==============================] - 1s 4ms/step - loss: 0.6187 - val_loss: 0.5899
Epoch 8/20
363/363 [==============================] - 1s 4ms/step - loss: 0.5930 - val_loss: 0.6116
Epoch 9/20
363/363 [==============================] - 1s 4ms/step - loss: 0.5697 - val_loss: 0.6095
Epoch 10/20
363/363 [==============================] - 1s 4ms/step - loss: 0.5487 - val_loss: 0.5161
Epoch 11/20
363/363 [==============================] - 1s 3ms/step - loss: 0.5286 - val_loss: 0.4910
Epoch 12/20
363/363 [==============================] - 1s 4ms/step - loss: 0.5115 - val_loss: 0.4832
Epoch 13/20
363/363 [==============================] - 1s 3ms/step - loss: 0.4972 - val_loss: 0.4574
Epoch 14/20
363/363 [==============================] - 1s 3ms/step - loss: 0.4849 - val_loss: 0.4465
Epoch 15/20
363/363 [==============================] - 1s 3ms/step - loss: 0.4748 - val_loss: 0.4355
Epoch 16/20
363/363 [==============================] - 1s 3ms/step - loss: 0.4662 - val_loss: 0.4291
Epoch 17/20
363/363 [==============================] - 1s 3ms/step - loss: 0.4587 - val_loss: 0.4225
Epoch 18/20
363/363 [==============================] - 1s 3ms/step - loss: 0.4524 - val_loss: 0.4190
Epoch 19/20
363/363 [==============================] - 1s 3ms/step - loss: 0.4469 - val_loss: 0.4179
Epoch 20/20
363/363 [==============================] - 1s 3ms/step - loss: 0.4419 - val_loss: 0.4159
162/162 [==============================] - 0s 2ms/step - loss: 0.4366
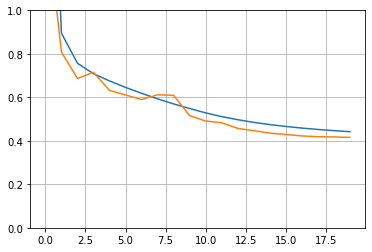
1 2 3 plt.plot(pd.DataFrame(history.history)) plt.grid(True ) plt.gca().set_ylim(0 , 1 )
(0.0, 1.0)
array([[0.6820665],
[1.432928 ],
[3.2171566]], dtype=float32)
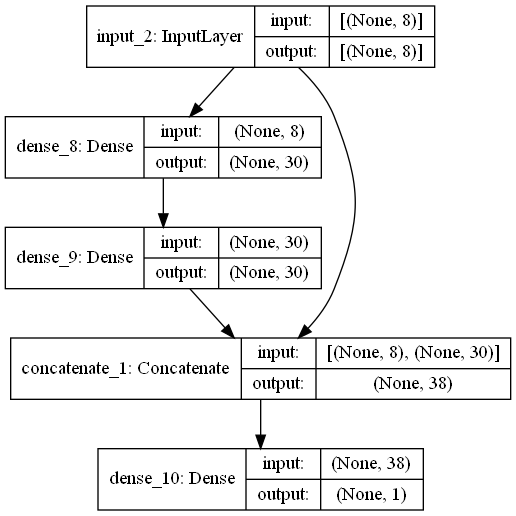
使用函数式API构建复杂模型 1 2 3 4 5 6 input_ = keras.layers.Input(shape=X_train.shape[1 :]) hidden1 = keras.layers.Dense(30 ,activation='relu' )(input_) hidden2 = keras.layers.Dense(30 ,activation='relu' )(hidden1) concat = keras.layers.Concatenate()([input_,hidden2]) output = keras.layers.Dense(1 )(concat) model = keras.Model(inputs=input_,outputs=output)
Model: "model_1"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_2 (InputLayer) [(None, 8)] 0
__________________________________________________________________________________________________
dense_8 (Dense) (None, 30) 270 input_2[0][0]
__________________________________________________________________________________________________
dense_9 (Dense) (None, 30) 930 dense_8[0][0]
__________________________________________________________________________________________________
concatenate_1 (Concatenate) (None, 38) 0 input_2[0][0]
dense_9[0][0]
__________________________________________________________________________________________________
dense_10 (Dense) (None, 1) 39 concatenate_1[0][0]
==================================================================================================
Total params: 1,239
Trainable params: 1,239
Non-trainable params: 0
__________________________________________________________________________________________________
1 keras.utils.plot_model(model,show_shapes=True )
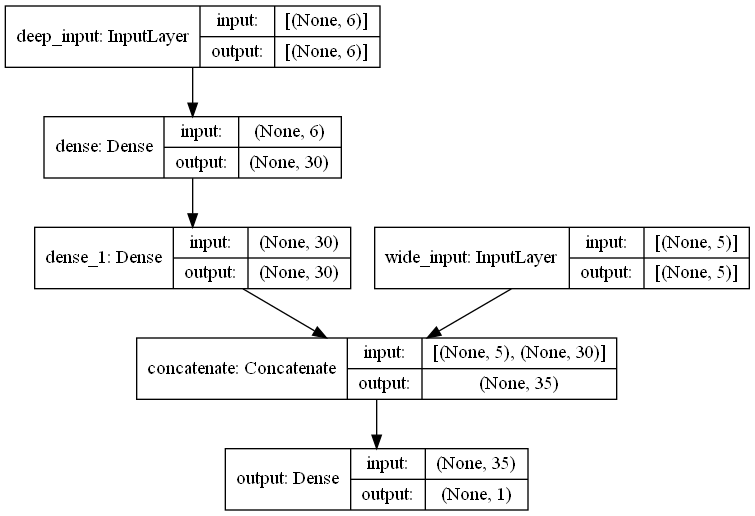
1 2 3 4 5 6 7 input_A = keras.layers.Input(shape=[5 ],name='wide_input' ) input_B = keras.layers.Input(shape=[6 ],name='deep_input' ) hidden1 = keras.layers.Dense(30 ,activation='relu' )(input_B) hidden2 = keras.layers.Dense(30 ,activation='relu' )(hidden1) concat = keras.layers.Concatenate()([input_A,hidden2]) output = keras.layers.Dense(1 ,name='output' )(concat) model = keras.Model(inputs=[input_A,input_B],outputs=[output])
Model: "model"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
deep_input (InputLayer) [(None, 6)] 0
__________________________________________________________________________________________________
dense (Dense) (None, 30) 210 deep_input[0][0]
__________________________________________________________________________________________________
wide_input (InputLayer) [(None, 5)] 0
__________________________________________________________________________________________________
dense_1 (Dense) (None, 30) 930 dense[0][0]
__________________________________________________________________________________________________
concatenate (Concatenate) (None, 35) 0 wide_input[0][0]
dense_1[0][0]
__________________________________________________________________________________________________
output (Dense) (None, 1) 36 concatenate[0][0]
==================================================================================================
Total params: 1,176
Trainable params: 1,176
Non-trainable params: 0
__________________________________________________________________________________________________
1 keras.utils.plot_model(model,show_shapes=True )
1 model.compile (loss='mse' ,optimizer=keras.optimizers.SGD(learning_rate=0.001 ))
注意:在创建模型时,我们制定了多个输入,我们在fit时就应该传入多个输入,在predict,evaluate时都应该有多个输入。
1 2 3 4 X_train_A, X_train_B = X_train[:,:5 ], X_train[:,2 :] X_valid_A, X_valid_B = X_valid[:,:5 ], X_valid[:,2 :] X_test_A, X_test_B = X_test[:,:5 ], X_test[:,2 :] X_new_A, X_new_B = X_test_A[:3 ], X_test_B[:3 ]
1 history = model.fit((X_train_A,X_train_B),y_train,validation_data=((X_valid_A,X_valid_B),y_valid),epochs=20 )
Epoch 1/20
363/363 [==============================] - 2s 4ms/step - loss: 2.6025 - val_loss: 5.7793
Epoch 2/20
363/363 [==============================] - 1s 4ms/step - loss: 0.8397 - val_loss: 2.4269
Epoch 3/20
363/363 [==============================] - 1s 4ms/step - loss: 0.6759 - val_loss: 1.3355
Epoch 4/20
363/363 [==============================] - 1s 3ms/step - loss: 0.6015 - val_loss: 0.9239
Epoch 5/20
363/363 [==============================] - 1s 4ms/step - loss: 0.5522 - val_loss: 0.6919
Epoch 6/20
363/363 [==============================] - 1s 3ms/step - loss: 0.5167 - val_loss: 0.5866
Epoch 7/20
363/363 [==============================] - 1s 3ms/step - loss: 0.4893 - val_loss: 0.5162
Epoch 8/20
363/363 [==============================] - 1s 4ms/step - loss: 0.4697 - val_loss: 0.4804
Epoch 9/20
363/363 [==============================] - 1s 4ms/step - loss: 0.4546 - val_loss: 0.4506
Epoch 10/20
363/363 [==============================] - 1s 4ms/step - loss: 0.4439 - val_loss: 0.4349
Epoch 11/20
363/363 [==============================] - 1s 4ms/step - loss: 0.4360 - val_loss: 0.4267
Epoch 12/20
363/363 [==============================] - 1s 4ms/step - loss: 0.4299 - val_loss: 0.4200
Epoch 13/20
363/363 [==============================] - 1s 4ms/step - loss: 0.4259 - val_loss: 0.4198
Epoch 14/20
363/363 [==============================] - 1s 4ms/step - loss: 0.4217 - val_loss: 0.4181
Epoch 15/20
363/363 [==============================] - 1s 3ms/step - loss: 0.4196 - val_loss: 0.4144
Epoch 16/20
363/363 [==============================] - 1s 4ms/step - loss: 0.4168 - val_loss: 0.4156
Epoch 17/20
363/363 [==============================] - 1s 4ms/step - loss: 0.4147 - val_loss: 0.4136
Epoch 18/20
363/363 [==============================] - 1s 4ms/step - loss: 0.4127 - val_loss: 0.4101
Epoch 19/20
363/363 [==============================] - 1s 4ms/step - loss: 0.4111 - val_loss: 0.4070
Epoch 20/20
363/363 [==============================] - 1s 4ms/step - loss: 0.4094 - val_loss: 0.4078
1 model.evaluate((X_test_A,X_test_B),y_test)
162/162 [==============================] - 0s 2ms/step - loss: 0.4078
0.40784752368927
1 model.predict((X_new_A,X_new_B))
array([[0.5327476],
[1.9329988],
[3.3600936]], dtype=float32)
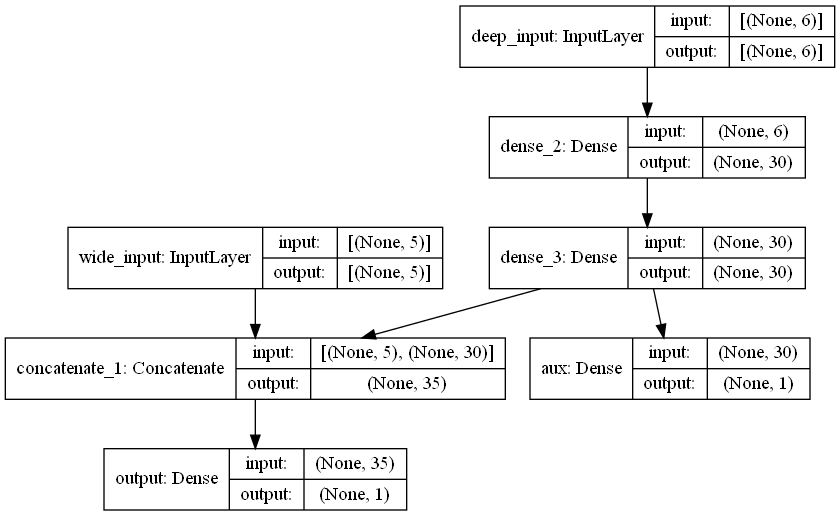
1 2 3 4 5 6 7 8 input_A = keras.layers.Input(shape=[5 ],name='wide_input' ) input_B = keras.layers.Input(shape=[6 ],name='deep_input' ) hidden1 = keras.layers.Dense(30 ,activation='relu' )(input_B) hidden2 = keras.layers.Dense(30 ,activation='relu' )(hidden1) concat = keras.layers.Concatenate()([input_A,hidden2]) output1 = keras.layers.Dense(1 ,name='output' )(concat) output2 = keras.layers.Dense(1 ,name='aux' )(hidden2) model = keras.Model(inputs=[input_A,input_B],outputs=[output1,output2])
Model: "model_1"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
deep_input (InputLayer) [(None, 6)] 0
__________________________________________________________________________________________________
dense_2 (Dense) (None, 30) 210 deep_input[0][0]
__________________________________________________________________________________________________
wide_input (InputLayer) [(None, 5)] 0
__________________________________________________________________________________________________
dense_3 (Dense) (None, 30) 930 dense_2[0][0]
__________________________________________________________________________________________________
concatenate_1 (Concatenate) (None, 35) 0 wide_input[0][0]
dense_3[0][0]
__________________________________________________________________________________________________
output (Dense) (None, 1) 36 concatenate_1[0][0]
__________________________________________________________________________________________________
aux (Dense) (None, 1) 31 dense_3[0][0]
==================================================================================================
Total params: 1,207
Trainable params: 1,207
Non-trainable params: 0
__________________________________________________________________________________________________
1 keras.utils.plot_model(model,show_shapes=True )
注意:每个输出都要有自己的损失函数,所以当我们编译模型时应该传递一系列的损失(如果传递单个损失,则默认所有输出使用相同的损失)。
默认情况下,Keras计算所有这些损失,并简单的相加得到最终的训练损失;而我们关注的是主要输出,所以要给主要输出更大的权重,我们可以通过设置参数loss_weights来指定不同损失的权重。除此之外,我们fit,evaluate时也要传入多个用于验证的数据。
1 model.compile (loss=['mse' ,'mse' ],loss_weights=[0.9 ,0.1 ],optimizer='sgd' )
1 history = model.fit([X_train_A,X_train_B],[y_train,y_train],epochs=20 ,validation_data=([X_valid_A,X_valid_B],[y_valid,y_valid]))
Epoch 1/20
363/363 [==============================] - 2s 6ms/step - loss: 0.5364 - output_loss: 0.4733 - aux_loss: 1.1042 - val_loss: 2.4807 - val_output_loss: 2.6077 - val_aux_loss: 1.3375
Epoch 2/20
363/363 [==============================] - 2s 5ms/step - loss: 0.5027 - output_loss: 0.4567 - aux_loss: 0.9175 - val_loss: 1.3039 - val_output_loss: 1.3301 - val_aux_loss: 1.0683
Epoch 3/20
363/363 [==============================] - 2s 5ms/step - loss: 0.4725 - output_loss: 0.4361 - aux_loss: 0.8008 - val_loss: 0.9919 - val_output_loss: 0.9801 - val_aux_loss: 1.0980
Epoch 4/20
363/363 [==============================] - 2s 5ms/step - loss: 0.4479 - output_loss: 0.4186 - aux_loss: 0.7117 - val_loss: 0.4309 - val_output_loss: 0.4022 - val_aux_loss: 0.6895
Epoch 5/20
363/363 [==============================] - 2s 5ms/step - loss: 0.4334 - output_loss: 0.4089 - aux_loss: 0.6546 - val_loss: 0.4091 - val_output_loss: 0.3853 - val_aux_loss: 0.6233
Epoch 6/20
363/363 [==============================] - 2s 5ms/step - loss: 0.4208 - output_loss: 0.3989 - aux_loss: 0.6178 - val_loss: 0.4338 - val_output_loss: 0.4149 - val_aux_loss: 0.6042
Epoch 7/20
363/363 [==============================] - 2s 5ms/step - loss: 0.4143 - output_loss: 0.3942 - aux_loss: 0.5945 - val_loss: 0.4099 - val_output_loss: 0.3919 - val_aux_loss: 0.5717
Epoch 8/20
363/363 [==============================] - 2s 5ms/step - loss: 0.4081 - output_loss: 0.3895 - aux_loss: 0.5754 - val_loss: 0.3863 - val_output_loss: 0.3680 - val_aux_loss: 0.5504
Epoch 9/20
363/363 [==============================] - 2s 5ms/step - loss: 0.4041 - output_loss: 0.3867 - aux_loss: 0.5606 - val_loss: 0.3876 - val_output_loss: 0.3707 - val_aux_loss: 0.5395
Epoch 10/20
363/363 [==============================] - 2s 5ms/step - loss: 0.3987 - output_loss: 0.3821 - aux_loss: 0.5485 - val_loss: 0.3737 - val_output_loss: 0.3570 - val_aux_loss: 0.5239
Epoch 11/20
363/363 [==============================] - 2s 5ms/step - loss: 0.3933 - output_loss: 0.3776 - aux_loss: 0.5348 - val_loss: 0.3769 - val_output_loss: 0.3604 - val_aux_loss: 0.5250
Epoch 12/20
363/363 [==============================] - 2s 5ms/step - loss: 0.3951 - output_loss: 0.3802 - aux_loss: 0.5291 - val_loss: 0.3697 - val_output_loss: 0.3540 - val_aux_loss: 0.5103
Epoch 13/20
363/363 [==============================] - 2s 5ms/step - loss: 0.3882 - output_loss: 0.3738 - aux_loss: 0.5178 - val_loss: 0.3646 - val_output_loss: 0.3488 - val_aux_loss: 0.5064
Epoch 14/20
363/363 [==============================] - 2s 5ms/step - loss: 0.3843 - output_loss: 0.3702 - aux_loss: 0.5115 - val_loss: 0.3543 - val_output_loss: 0.3388 - val_aux_loss: 0.4932
Epoch 15/20
363/363 [==============================] - 2s 5ms/step - loss: 0.3813 - output_loss: 0.3680 - aux_loss: 0.5011 - val_loss: 0.3764 - val_output_loss: 0.3620 - val_aux_loss: 0.5061
Epoch 16/20
363/363 [==============================] - 2s 5ms/step - loss: 0.3886 - output_loss: 0.3752 - aux_loss: 0.5085 - val_loss: 0.6404 - val_output_loss: 0.6423 - val_aux_loss: 0.6231
Epoch 17/20
363/363 [==============================] - 2s 5ms/step - loss: 0.3806 - output_loss: 0.3679 - aux_loss: 0.4952 - val_loss: 0.3480 - val_output_loss: 0.3344 - val_aux_loss: 0.4705
Epoch 18/20
363/363 [==============================] - 2s 5ms/step - loss: 0.3703 - output_loss: 0.3575 - aux_loss: 0.4855 - val_loss: 0.3608 - val_output_loss: 0.3481 - val_aux_loss: 0.4753
Epoch 19/20
363/363 [==============================] - 2s 5ms/step - loss: 0.3666 - output_loss: 0.3543 - aux_loss: 0.4766 - val_loss: 0.3572 - val_output_loss: 0.3452 - val_aux_loss: 0.4650
Epoch 20/20
363/363 [==============================] - 2s 5ms/step - loss: 0.3699 - output_loss: 0.3584 - aux_loss: 0.4740 - val_loss: 0.3714 - val_output_loss: 0.3610 - val_aux_loss: 0.4657
1 2 total_loss, main_loss, aux_loss = model.evaluate([X_test_A,X_test_B],[y_test,y_test]) y_pred_main, y_aux = model.predict([X_new_A,X_new_B])
162/162 [==============================] - 0s 3ms/step - loss: 0.3888 - output_loss: 0.3806 - aux_loss: 0.4621
使用子类API构建动态模型 通过对keras.Model继承,在构造函数中创建所需要的层,再在call方法中执行所需的计算即可。但这样Keras无法对其进行检查。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 class myModel (keras.Model ): def __init__ (self,units=30 ,activation='relu' ,**kwargs ): super ().__init__(**kwargs) self.hidden1 = keras.layers.Dense(units,activation=activation) self.hidden2 = keras.layers.Dense(units,activation=activation) self.main_output = keras.layers.Dense(1 ) self.aux = keras.layers.Dense(1 ) def call (self,inputs ): input_A, input_B = inputs hidden1 = self.hidden1(input_B) hidden2 = self.hidden2(hidden1) concat = keras.layers.concatenate([input_A,hidden2]) aux = self.aux(hidden2) main_output = self.main_output(concat) return main_output, aux
使用回调函数 fit()方法接收一个callbacks参数,该参数可以指定Keras在训练开始和结束时(或是处理每个批量之前和之后)将调用对象列表。
下面介绍:ModelCheckpoint回调,定期保存模型的检查点;EarlyStopping回调,多个轮次在验证集上没有进展,模型训练就会中断并回滚到最佳模型。
我们也可以通过继承keras.callbacks.Callback,重写其中的方法来自定义自己的回调函数。
1 2 3 checkpoint_cb = keras.callbacks.ModelCheckpoint('my_model.h5' ,save_best_only=True ) model.compile (loss='mse' ,optimizer=keras.optimizers.SGD(learning_rate=0.001 )) history = model.fit(X_train,y_train,epochs=20 ,validation_data=(X_valid,y_valid),callbacks=[checkpoint_cb])
Epoch 1/20
363/363 [==============================] - 1s 4ms/step - loss: 2.1240 - val_loss: 0.7047
Epoch 2/20
363/363 [==============================] - 1s 4ms/step - loss: 0.6714 - val_loss: 0.6753
Epoch 3/20
363/363 [==============================] - 1s 4ms/step - loss: 0.6299 - val_loss: 0.5984
Epoch 4/20
363/363 [==============================] - 1s 3ms/step - loss: 0.5988 - val_loss: 0.5573
Epoch 5/20
363/363 [==============================] - 1s 3ms/step - loss: 0.5749 - val_loss: 0.5342
Epoch 6/20
363/363 [==============================] - 1s 3ms/step - loss: 0.5565 - val_loss: 0.5197
Epoch 7/20
363/363 [==============================] - 1s 3ms/step - loss: 0.5413 - val_loss: 0.6011
Epoch 8/20
363/363 [==============================] - 1s 3ms/step - loss: 0.5266 - val_loss: 0.4995
Epoch 9/20
363/363 [==============================] - 1s 3ms/step - loss: 0.5164 - val_loss: 0.5106
Epoch 10/20
363/363 [==============================] - 1s 3ms/step - loss: 0.5055 - val_loss: 0.4727
Epoch 11/20
363/363 [==============================] - 1s 3ms/step - loss: 0.4972 - val_loss: 0.5377
Epoch 12/20
363/363 [==============================] - 1s 3ms/step - loss: 0.4884 - val_loss: 0.5494
Epoch 13/20
363/363 [==============================] - 1s 3ms/step - loss: 0.4810 - val_loss: 0.5290
Epoch 14/20
363/363 [==============================] - 1s 3ms/step - loss: 0.4738 - val_loss: 0.4608
Epoch 15/20
363/363 [==============================] - 1s 3ms/step - loss: 0.4683 - val_loss: 0.4647
Epoch 16/20
363/363 [==============================] - 1s 3ms/step - loss: 0.4619 - val_loss: 0.4790
Epoch 17/20
363/363 [==============================] - 1s 3ms/step - loss: 0.4569 - val_loss: 0.4285
Epoch 18/20
363/363 [==============================] - 1s 3ms/step - loss: 0.4517 - val_loss: 0.4691
Epoch 19/20
363/363 [==============================] - 1s 4ms/step - loss: 0.4460 - val_loss: 0.4570
Epoch 20/20
363/363 [==============================] - 1s 3ms/step - loss: 0.4418 - val_loss: 0.4153
1 2 3 earlystop = keras.callbacks.EarlyStopping(patience=10 ,restore_best_weights=True ) model.compile (loss='mse' ,optimizer='sgd' ) history = model.fit(X_train,y_train,epochs=20 ,validation_data=(X_valid,y_valid),callbacks=[checkpoint_cb,earlystop])
Epoch 1/20
363/363 [==============================] - 2s 4ms/step - loss: 0.4373 - val_loss: 0.7789
Epoch 2/20
363/363 [==============================] - 1s 4ms/step - loss: 0.4349 - val_loss: 3.3366
Epoch 3/20
363/363 [==============================] - 1s 3ms/step - loss: 0.5176 - val_loss: 11.5161
Epoch 4/20
363/363 [==============================] - 1s 4ms/step - loss: 0.4472 - val_loss: 5.0992
Epoch 5/20
363/363 [==============================] - 1s 3ms/step - loss: 0.3935 - val_loss: 24.5138
Epoch 6/20
363/363 [==============================] - 1s 4ms/step - loss: 0.7370 - val_loss: 38.8524
Epoch 7/20
363/363 [==============================] - 1s 3ms/step - loss: 0.5221 - val_loss: 368.9537
Epoch 8/20
363/363 [==============================] - 1s 4ms/step - loss: 0.6238 - val_loss: 80.9212
Epoch 9/20
363/363 [==============================] - 1s 4ms/step - loss: 0.5975 - val_loss: 414.6273
Epoch 10/20
363/363 [==============================] - 1s 3ms/step - loss: 0.7681 - val_loss: 190.2743
Epoch 11/20
363/363 [==============================] - 1s 3ms/step - loss: 0.7865 - val_loss: 154.1239
1 2 3 4 class myCallback (keras.callbacks.Callback ): def on_epoch_end (self,epoch,logs ): print ('\nval/train:{:.2}' .format (logs['val_loss' ]/logs['loss' ])) my_cb = myCallback()
1 2 model.compile (loss='mse' ,optimizer=keras.optimizers.SGD(learning_rate=0.001 )) history = model.fit(X_train,y_train,epochs=20 ,validation_data=(X_valid,y_valid),callbacks=[checkpoint_cb,my_cb])
Epoch 1/20
363/363 [==============================] - 2s 4ms/step - loss: 1.8173 - val_loss: 4.5359
val/train:2.5
Epoch 2/20
363/363 [==============================] - 2s 4ms/step - loss: 0.7135 - val_loss: 1.6776
val/train:2.4
Epoch 3/20
363/363 [==============================] - 1s 3ms/step - loss: 0.6339 - val_loss: 0.6325
val/train:1.0
Epoch 4/20
363/363 [==============================] - 1s 3ms/step - loss: 0.5837 - val_loss: 0.5607
val/train:0.96
Epoch 5/20
363/363 [==============================] - 1s 3ms/step - loss: 0.5529 - val_loss: 0.5251
val/train:0.95
Epoch 6/20
363/363 [==============================] - 1s 3ms/step - loss: 0.5275 - val_loss: 0.5709
val/train:1.1
Epoch 7/20
363/363 [==============================] - 1s 4ms/step - loss: 0.5105 - val_loss: 0.4771
val/train:0.93
Epoch 8/20
363/363 [==============================] - 1s 3ms/step - loss: 0.4933 - val_loss: 0.4701
val/train:0.95
Epoch 9/20
363/363 [==============================] - 1s 3ms/step - loss: 0.4797 - val_loss: 0.4542
val/train:0.95
Epoch 10/20
363/363 [==============================] - 1s 3ms/step - loss: 0.4682 - val_loss: 0.4373
val/train:0.93
Epoch 11/20
363/363 [==============================] - 1s 3ms/step - loss: 0.4588 - val_loss: 0.4422
val/train:0.96
Epoch 12/20
363/363 [==============================] - 1s 3ms/step - loss: 0.4514 - val_loss: 0.4256
val/train:0.94
Epoch 13/20
363/363 [==============================] - 1s 3ms/step - loss: 0.4444 - val_loss: 0.4224
val/train:0.95
Epoch 14/20
363/363 [==============================] - 1s 3ms/step - loss: 0.4384 - val_loss: 0.4104
val/train:0.94
Epoch 15/20
363/363 [==============================] - 1s 3ms/step - loss: 0.4329 - val_loss: 0.4071
val/train:0.94
Epoch 16/20
363/363 [==============================] - 1s 3ms/step - loss: 0.4281 - val_loss: 0.4084
val/train:0.95
Epoch 17/20
363/363 [==============================] - 1s 4ms/step - loss: 0.4234 - val_loss: 0.3962
val/train:0.94
Epoch 18/20
363/363 [==============================] - 1s 3ms/step - loss: 0.4198 - val_loss: 0.3929
val/train:0.94
Epoch 19/20
363/363 [==============================] - 1s 3ms/step - loss: 0.4160 - val_loss: 0.3929
val/train:0.94
Epoch 20/20
363/363 [==============================] - 1s 4ms/step - loss: 0.4127 - val_loss: 0.3911
val/train:0.95
微调神经网络超参数 1 2 3 4 5 6 7 8 9 def build_model (n_hidden=1 ,n_neurons=30 ,lr=0.003 ,input_shape=[8 ] ): model = keras.models.Sequential() model.add(keras.layers.InputLayer(input_shape=input_shape)) for i in range (n_hidden): model.add(keras.layers.Dense(n_neurons,activation='relu' )) model.add(keras.layers.Dense(1 )) optimizer = keras.optimizers.SGD(learning_rate=lr) model.compile (loss='mse' ,optimizer=optimizer) return model
1 keras_reg = keras.wrappers.scikit_learn.KerasRegressor(build_model)
1 2 from scipy.stats import reciprocalfrom sklearn.model_selection import RandomizedSearchCV
1 2 3 4 5 6 param = {'n_hidden' :[0 ,1 ,2 ,3 ], 'n_neurons' :np.arange(1 ,100 ), 'lr' :reciprocal(3e-4 ,3e-2 )} rnd_search = RandomizedSearchCV(keras_reg,param,n_iter=10 ,cv=3 ) rnd_search.fit(X_train,y_train,epochs=100 ,validation_data=(X_valid,y_valid), callbacks=keras.callbacks.EarlyStopping(patience=10 ))
Epoch 1/100
242/242 [==============================] - 5s 7ms/step - loss: 3.5815 - val_loss: 2.2888
Epoch 2/100
242/242 [==============================] - 1s 6ms/step - loss: 1.7560 - val_loss: 2.5086
Epoch 3/100
242/242 [==============================] - 1s 6ms/step - loss: 1.2191 - val_loss: 1.9225
Epoch 4/100
242/242 [==============================] - 2s 6ms/step - loss: 0.9811 - val_loss: 0.9753
Epoch 5/100
242/242 [==============================] - 2s 8ms/step - loss: 0.8616 - val_loss: 0.8079
Epoch 6/100
242/242 [==============================] - 2s 8ms/step - loss: 0.8030 - val_loss: 0.7575
Epoch 7/100
242/242 [==============================] - 2s 8ms/step - loss: 0.7713 - val_loss: 0.7350
Epoch 8/100
242/242 [==============================] - 2s 7ms/step - loss: 0.7513 - val_loss: 0.7270
Epoch 9/100
242/242 [==============================] - 2s 6ms/step - loss: 0.7336 - val_loss: 0.7480
Epoch 10/100
242/242 [==============================] - 2s 8ms/step - loss: 0.7184 - val_loss: 0.6900
......
Epoch 43/100
363/363 [==============================] - 1s 4ms/step - loss: 0.2850 - val_loss: 0.3304
Epoch 44/100
363/363 [==============================] - 1s 4ms/step - loss: 0.2924 - val_loss: 0.3627
Epoch 45/100
363/363 [==============================] - 1s 4ms/step - loss: 0.2917 - val_loss: 0.2973
Epoch 46/100
363/363 [==============================] - 2s 4ms/step - loss: 0.2852 - val_loss: 0.3063
Epoch 47/100
363/363 [==============================] - 1s 4ms/step - loss: 0.2834 - val_loss: 0.2980
RandomizedSearchCV(cv=3,
estimator=<keras.wrappers.scikit_learn.KerasRegressor object at 0x00000204C9FA0700>,
param_distributions={'lr': <scipy.stats._distn_infrastructure.rv_frozen object at 0x00000204CA37D970>,
'n_hidden': [0, 1, 2, 3],
'n_neurons': array([ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17,
18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34,
35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51,
52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64, 65, 66, 67, 68,
69, 70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 80, 81, 82, 83, 84, 85,
86, 87, 88, 89, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99])})
1 2 3 print (rnd_search.best_params_)print (rnd_search.best_score_)model = rnd_search.best_estimator_.model
{'lr': 0.006537702460946492, 'n_hidden': 2, 'n_neurons': 97}
-0.3313012421131134
1 2 print (model.predict(X_test[:8 ]))print (y_test[:8 ])
[[0.4486066]
[1.2853019]
[4.6888404]
[2.4607358]
[3.0793304]
[1.7062786]
[2.475378 ]
[1.6391015]]
[0.477 0.458 5.00001 2.186 2.78 1.587 1.982 1.575 ]
使用Tensorboard可视化 1 2 3 4 5 6 7 def get_dir (): import os import time root = os.path.join(os.curdir,'my_logs' ) now = time.strftime('run_%Y_%m_%d-%H_%M_%S' ) log_dir = os.path.join(root,now) return log_dir
1 2 run_dir = get_dir() run_dir
'.\\my_logs\\run_2021_08_19-08_32_56'
1 2 3 tensorboard_cb = keras.callbacks.TensorBoard(run_dir) model.compile (loss='mse' ,optimizer=keras.optimizers.SGD(learning_rate=0.001 )) model.fit(X_train,y_train,epochs=20 ,validation_data=(X_valid,y_valid),callbacks=[tensorboard_cb])
Epoch 1/20
363/363 [==============================] - 4s 6ms/step - loss: 1.5561 - val_loss: 1.5187
Epoch 2/20
363/363 [==============================] - 2s 6ms/step - loss: 0.6865 - val_loss: 0.6418
Epoch 3/20
363/363 [==============================] - 2s 6ms/step - loss: 0.6270 - val_loss: 0.6595
Epoch 4/20
363/363 [==============================] - 2s 6ms/step - loss: 0.5937 - val_loss: 0.5843
Epoch 5/20
363/363 [==============================] - 2s 6ms/step - loss: 0.5651 - val_loss: 0.5278
Epoch 6/20
363/363 [==============================] - 2s 6ms/step - loss: 0.5430 - val_loss: 0.5624
Epoch 7/20
363/363 [==============================] - 2s 5ms/step - loss: 0.5248 - val_loss: 0.5022
Epoch 8/20
363/363 [==============================] - 2s 4ms/step - loss: 0.5094 - val_loss: 0.4765
Epoch 9/20
363/363 [==============================] - 1s 4ms/step - loss: 0.4959 - val_loss: 0.4660
Epoch 10/20
363/363 [==============================] - 1s 3ms/step - loss: 0.4840 - val_loss: 0.4719
Epoch 11/20
363/363 [==============================] - 1s 3ms/step - loss: 0.4745 - val_loss: 0.4435
Epoch 12/20
363/363 [==============================] - 1s 3ms/step - loss: 0.4662 - val_loss: 0.4403
Epoch 13/20
363/363 [==============================] - 1s 3ms/step - loss: 0.4587 - val_loss: 0.4307
Epoch 14/20
363/363 [==============================] - 1s 4ms/step - loss: 0.4518 - val_loss: 0.4217
Epoch 15/20
363/363 [==============================] - 1s 3ms/step - loss: 0.4460 - val_loss: 0.4219
Epoch 16/20
363/363 [==============================] - 1s 3ms/step - loss: 0.4410 - val_loss: 0.4171
Epoch 17/20
363/363 [==============================] - 1s 3ms/step - loss: 0.4357 - val_loss: 0.4126
Epoch 18/20
363/363 [==============================] - 1s 3ms/step - loss: 0.4316 - val_loss: 0.4067
Epoch 19/20
363/363 [==============================] - 1s 4ms/step - loss: 0.4276 - val_loss: 0.4016
Epoch 20/20
363/363 [==============================] - 1s 3ms/step - loss: 0.4236 - val_loss: 0.4090
1 2 3 4 5 6 7 8 9 10 11 from tensorflow import summarywriter = summary.create_file_writer(get_dir()) with writer.as_default(): for i in range (1 ,1000 +1 ): summary.scalar('my_scalar' ,np.sin(i/10 ),i) data = (np.random.randn(100 )+2 )*i/1000 summary.histogram('my_histogram' ,data,buckets=50 ,step=i) img = np.random.rand(2 ,32 ,32 ,2 ) summary.image('my_img' ,img*i/1000 ,step=i) txt = ['step is ' +str (i),'the square is ' +str (i**2 )] summary.text('my_text' ,txt,step=i)